Big Data in Cloud Computing review and Opportunities Introduction
Introduction
The rise of big data in daily life is on the rise in almost all domains and applications. Its combination with cloud computing is a major attraction in IT sector. While big data deals with large scale data, cloud computing deals with the infrastructure of the data storage. The concerns are simplified when they are used in combination, and are largely effective. Hence, they are used widely for organizational data solutions. The other advantage is that both these technologies are still in their evolutionary stage, where they are getting improved regularly, which would further be beneficial for the future with respect to cost and data analytics. A suitable customer may start using Cloud Computing when in need of quick deployment and scaling of their applications. The applications may deal with sensitive data, hence there must be a strict compliance on what must be stored on the cloud due to security reasons. Big data cannot be considered as a replacement for relational database systems and big data solves specific problem statement related to larger data sets and most of the large data sets do not deal with small data. This concept is explained in detail for this work


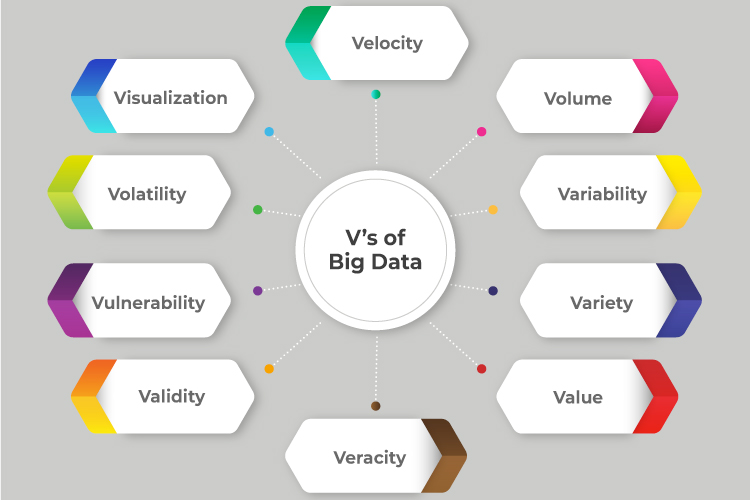
The paper explains in detail the various characteristics of Big Data by formulating the ten Vs. The ten characteristics mentioned are velocity, value, volume, variety, variability, validity, veracity, volatility, vulnerability, and visualization as shown in figure.
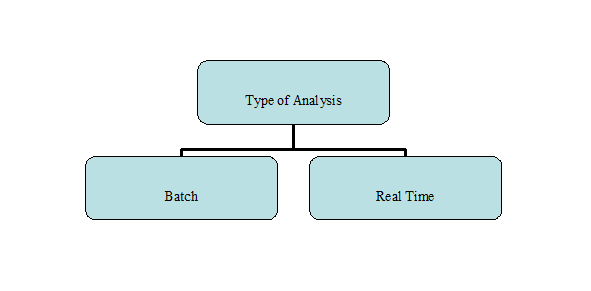
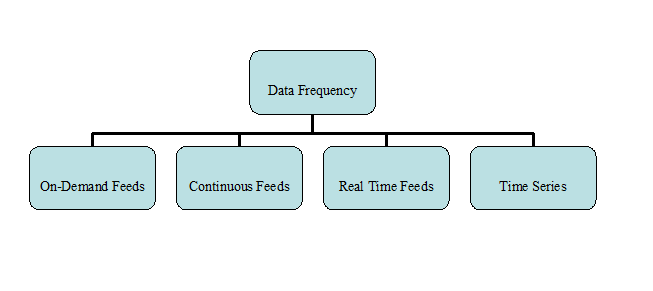
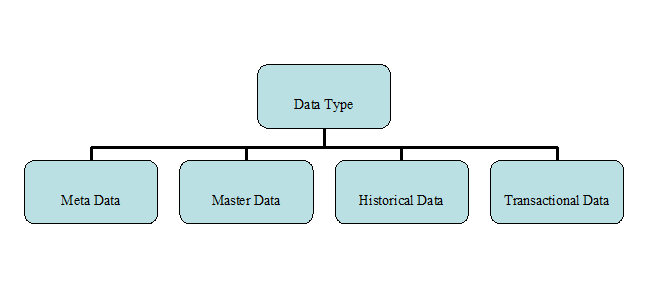
The paper also deals with classification of big data. It is classified through 7 different categories. Some of these classifications are visualized below.
Type of Analysis
Data Frequency
Data Type
Hardware
Data Consumers
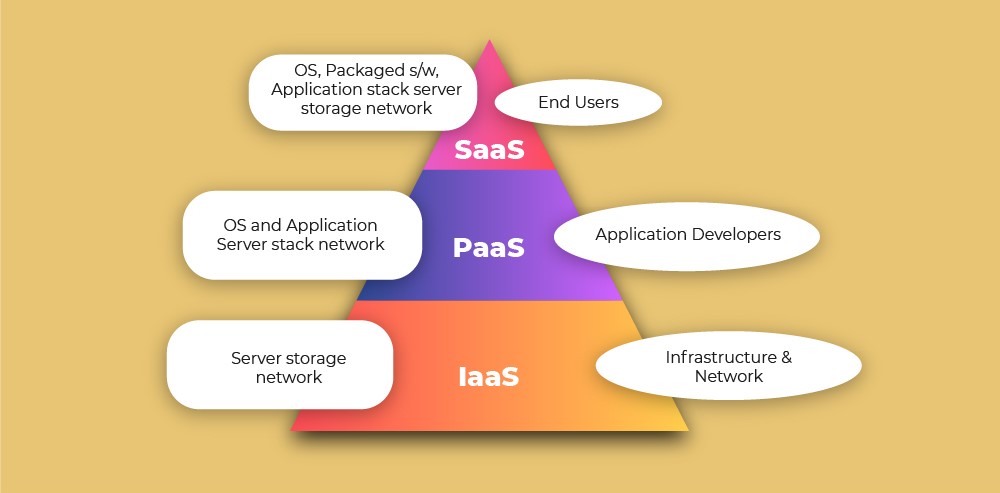
After explanation of big data, the paper moves on to cloud computing. Cloud computing delivers computing services like servers, storage, databases, networking, software, analytics and intelligence over the internet for faster innovation, flexible resources, heavy computation, parallel data processing and economies of scale. The organizations are empowered in order to concentrate more on core business by completely abstracting computation, storage and network resources to workloads. The various types of cloud computing explained here are
The relationship between the cloud computing and big data are explained in detail, in the paper. Virtualization is discussed as the process of creating a software-based, or virtual representation of virtual desktop, servers, storage, operating system and network resources. It creates a virtual environment on an existing server to run desired applications, without interfering with any of the other services provided by the server or host platform to other users.
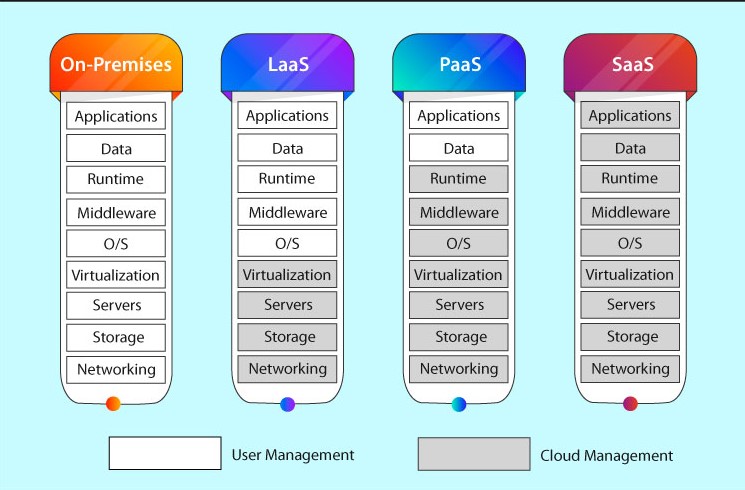
Cloud computing delivers computing services such as servers, storage, databases, networking, software, analytics and intelligence over the internet for faster innovation, flexible resources, heavy computation, parallel data processing and economies of scale. It empowers the organizations to concentrate on core business by completely abstracting computation, storage and network resources to workloads as needed and tap into an abundance of prebuilt services. Figure shows the differences between on-premise and cloud services. It shows the services offered by each computing layer and differences between them
It is a technique, which allows to share a single physical instance of a resource or an application among multiple customers and organizations. It does by assigning a logical name to a physical storage and providing a pointer to that physical resource when demanded.
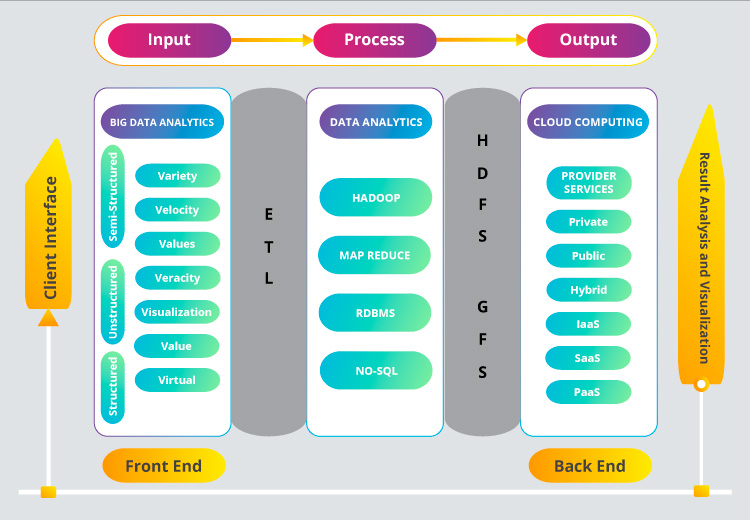
The relationship between big data and cloud computing follows input, processing and output models. The input is the big data obtained from various data sources such as cellular and other smart devices in either structured, unstructured or semi-structured format. This voluminous data is cleaned and then stored using Hadoop or other data stores. The stored data is in turn processed through cloud computing tools and techniques for providing services. Processing steps includes all the tasks required to transform input data. Output represents the value obtained after data is being processed for analysis and visualization
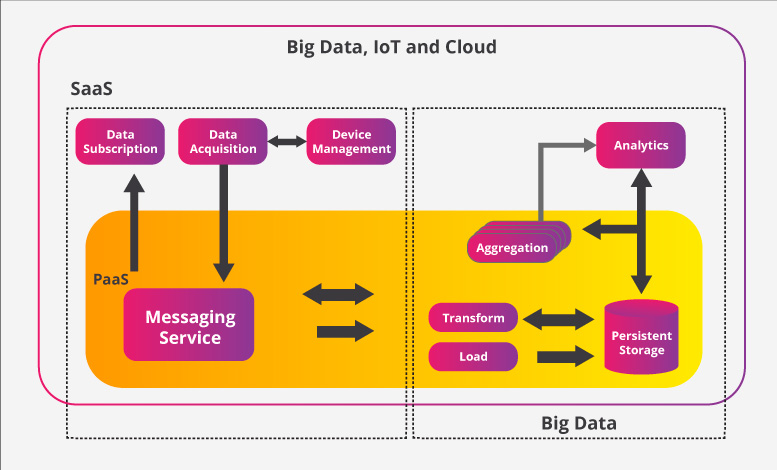
Case Studies

The types of databases and its significance in cloud computing is discussed along with the Hadoop tools. Modern databases need to handle large volume and different variety of data formats. They are expected to deliver extreme performance, provide high input/output operations per second required to deliver data to analytics tools and scale both horizontally and vertically to handle the dynamic data growth. Database architects have produced NoSQL and NewSQL as alternatives to relational database. NoSQL supports structured, semi-structured and unstructured data. It scales horizontally and provides BASE transactions. NewSQL is a new approach to relational databases that combines ACID transactions of RDBMSs and horizontal scalability of NoSQL. Below are characteristics of relational database, NoSQL and NewSQL.
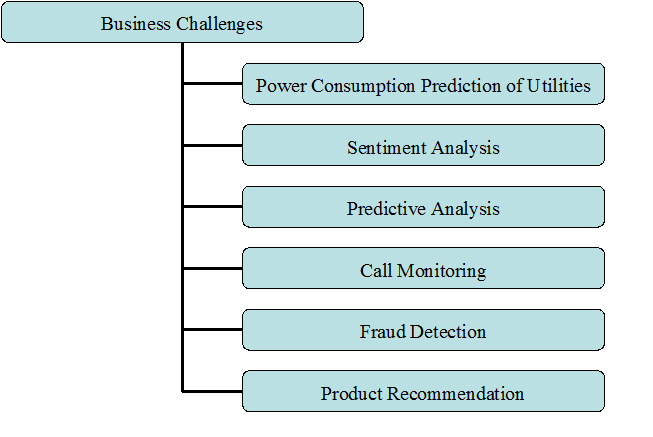
The challenges faced is also discussed. Cloud computing has been used as a standard solution for handling and processing big data. Despite all the advantages of integration between big data and cloud computing, there are several challenges in data transmission, data storage, data transformation, data quality, privacy, governance. Other than these, there are also other business challenges
An significant overview of big data applications in cloud computing has been discussed in the paper along with its challenges in storing, transformation, processing data and some good design principles which could lead to further research.
 Next Post
Next Post